PE File Rich Header
The Rich Header is a data structure that is only present in PE files developed in a Microsoft IDE. It’s considered an undocumented feature and Microsoft has never publicly disclosed its exact purpose, but researchers and malware developers have found ways to learn more about it and also take advantage of it.
The Rich Header is located after the DOS Stub and just before the PE Signature.
Let’s take a look at the rich header in PE-Bear:
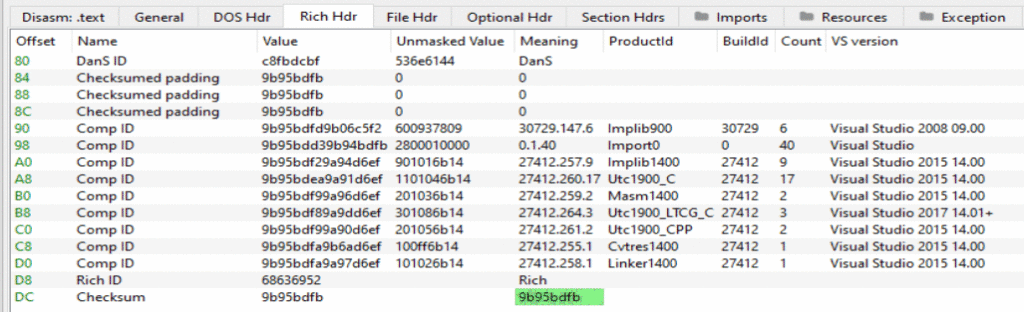
The rich header consists of:
- A bunch of XORed data
- The “Rich” keyword
- An XOR key (checksum) that can be used to decrypt the first part of the header
I found it easy to understand the rich header by starting at the end, which is how it must be parsed. The end of the rich header is demarked by the keyword “Rich”, or 0x68636952. PE-Bear calls this the ‘Rich ID’. It allows for easy identification of the Rich Header.
Immediately following the “Rich” keyword is a checksum that functions as an XOR key. It can be used to decrypt the rest of the header. If we use the key to XOR the data, working our way back we will find the DWORD “DanS” (0x536e6144) at the beginning of the header. Following this are three null DWORDs used for padding.
The rest of the rich header consists of data that fingerprints build information of the executable. Each entry has a Build Number, Product ID, and Count. PE-Bear does a phenomenal job of automatically parsing all of this for us.
Why the Rich Header is Important for Malware Development
Malware analysts are incredibly sophisticated, and they can use the rich header to glean information about malware or its developers.
At the surface level, a rich header can be used to identify the technologies involved in the development of a piece of malware: C, C++, Assembly, Visual Studio etc. But the rich header can also be used as a signature or fingerprint as well. The product counts of the rich header can be used as an indication of the project size. The checksum can be used by itself as a signature.
Malware authors can manipulate a rich header in various ways, including (but not limited to):
- Deleting the rich header to avoid fingerprinting and analysis
- Modifying it to place the blame on another group
- Modifying it as an easter egg
- Modifying it to make it look more like a legitimate executable
Other Resources for Learning About the Rich Header
I found it quite rewarding to spend a bit of time learning about the rich header. I first learned about it on 0xRick’s blog, which contains a good description and also a script to parse rich header data.
In particular, this article from VirusBulletin does an excellent job of breaking down the details of the Rich Header and how it is used (and often unwisely ignored) by malware developers and analysts.